Human Factors + Experience Engineering Lab (HFXE)
Discovering and Inventing for Human-Centered SE and AI
My research advances human-centered software engineering by uncovering the behaviors of problem-solving professionals and inventing intelligent, inclusive solutions at the intersection of software engineering (SE), human-computer interaction (HCI), and artificial intelligence (AI). I study how diverse individuals—including professional software engineers, end-user programmers, novices, and those from historically underrepresented groups—engage in solo, team-based, and human–AI programming contexts, including remote and technology-mediated collaboration. Through a rigorous, iterative process grounded in empirical inquiry, theory-building, and systematic evaluation, I produce novel strategies, frameworks, algorithms, visualizations, and tools that bridge human intent with machine execution—expanding the boundaries of inclusive, experience-centered software engineering. View my Research Statement (as of July 2025).
Research Projects:
Human-AI Pair Programming Agents


What if your coding partner were an intelligent, supportive agent—always available, never judgmental, and trained to collaborate like a real teammate? Since 2018, our research has been exploring this future through PairBuddy, a conversational agent designed to bring the benefits of pair programming to everyone.
At the time, no conversational agents supported software development—even though programming is inherently collaborative and communicative. Motivated by this gap, we launched one of the earliest efforts to explore inclusive AI-driven pair programming, with support from an NSF CAREER Award.
Built at the intersection of HCI, AI, education, and cognitive science, PairBuddy is more than just a code assistant. It is designed to support programmers through both technical assistance and social collaboration—fostering confidence, engagement, and equitable learning experiences.
Guided by inclusive design principles and refined through real-world studies, our work aims to shape the next generation of intelligent, collaborative tools for software development. We're also building open datasets, agent prototypes, and educational resources to support the broader research and teaching community.
NSF CAREER Award | ACM CHI Honorable Mention
Utilizing Agents' Collective Foraging Behavior

Just as ants leave pheromone trails and honeybees perform waggle dances to guide others, developers also leave behind behavioral traces—commit logs, navigation paths, and web searches—that can be harnessed to support others working on similar tasks. This research explores how these digital trails reflect collective intelligence and how we can use them to support efficient information seeking in software teams.
Since 2019, our research has leveraged Information Foraging Theory—a cognitive framework for understanding how people seek and evaluate information—to study how developers explore complex digital environments such as IDEs, GitHub, Stack Overflow, and the web. We have extended the theory beyond individual behavior to model how teams forage collectively, shaped by social cues, evolving goals, and task context. This work is supported by a U.S. Air Force Young Investigator Program (YIP) Award.
Our work has led to the development of new theoretical frameworks, predictive models, and cognitive tools that aim to reduce the burden of information overload, improve collaboration, and support inclusive decision-making in software development. These insights are informing the next generation of intelligent developer tools for both solo and remote collaborative work.
U.S. Air Force Young Investigator Program (YIP) Award | Best Paper Award (ACM CHI) | Honorable Mention Award (ACM CHI)
Metacognition and Social Cognition in Remote Software Teams
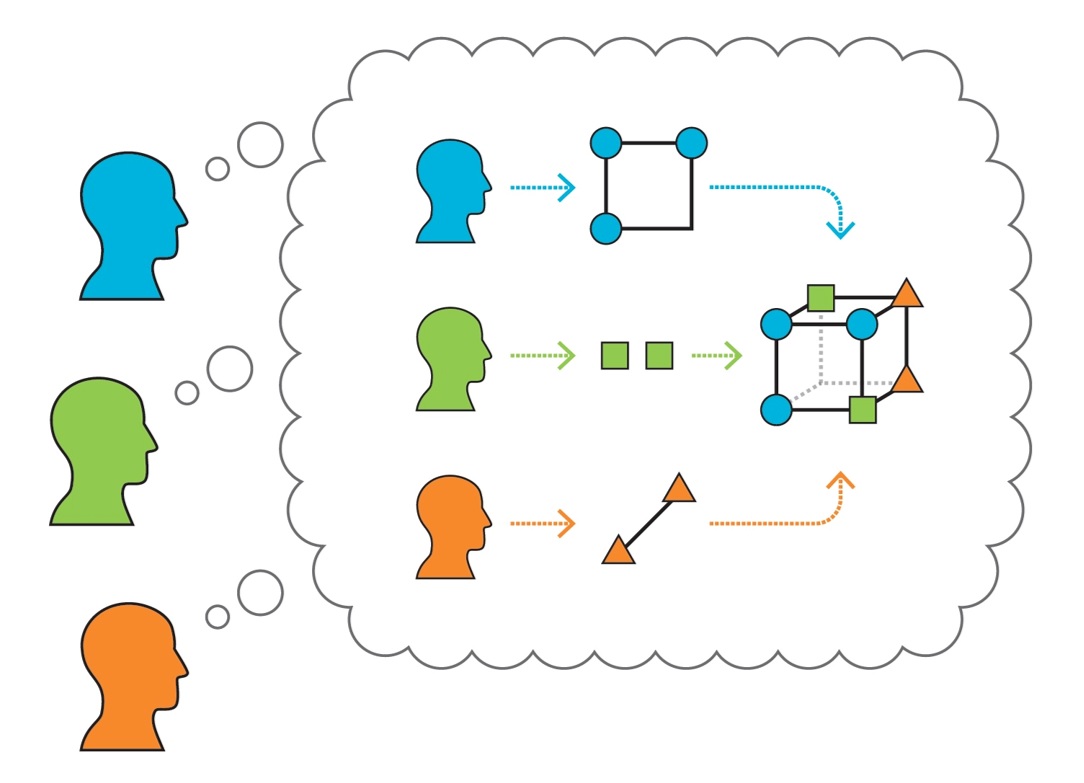
Successful teamwork in software development isn’t just about writing good code—it also depends on how team members think, reflect, and adapt during collaboration. This project explores how individuals and teams manage their thinking, especially in remote settings where social cues are limited.
In a study with 10 remote software teams, we observed that experienced developers were better at staying confident and focused during difficult tasks. In contrast, newer developers often struggled with self-doubt, especially when working independently. These patterns suggest that self-awareness and regulation—called metacognition—play a vital role in team performance.
We are now expanding this work to explore how teams reflect on each other’s thinking—known as social metacognition—to better understand how team communication and support influence shared success. This line of research aims to inform tools and practices that support healthier, more effective team dynamics in remote software development.
Inclusive Collaboration in Software Teams
The rise of remote and hybrid work has reshaped how software teams collaborate—but most platforms overlook the role of social identities like gender and race in shaping those interactions. This research investigates how these identities influence communication, task-sharing, and team dynamics in programming environments.
Drawing from software engineering, HCI, and organizational psychology, our work develops theoretical models and practical tools to support inclusive, equitable collaboration. We aim to design systems that recognize identity-based differences and proactively foster effective teamwork across diverse teams.
Our studies have uncovered critical challenges such as unequal task delegation, higher interruption rates, and reduced confidence in mixed-identity teams. At the same time, we’ve observed promising patterns of shared leadership and productivity that inclusive tools can help amplify.
We are also advancing equity-centered research practices by identifying structural and interpersonal barriers to participation and creating more inclusive research designs. Our work introduces new strategies for recruiting, supporting, and studying participants from underrepresented groups in computing.
Based on our 3Cs framework—communication, coordination, and collaboration—we are building a series of interventions:
- RemoteCollabEval: a structured method for detecting inclusivity issues in collaboration tools ACM DIS Honorable Mention
- PairEquity: an AI-powered facilitator that identifies real-time interaction imbalances and provides inclusive feedback
- 3Cs in Education: a classroom initiative helping students recognize and navigate equity challenges in team projects
Recruiting Diverse Participants in Software Engineering Research

Inclusive research begins with inclusive participation. This project focuses on designing ethical, participant-centered approaches to broaden who gets included in software engineering studies.
Through interviews with computing researchers, we explored the challenges of reaching underrepresented communities and co-developed practical strategies for more equitable recruitment—emphasizing trust, transparency, and accessibility in study design.
A key contribution of this work is a customizable framework that maps participant identities to preferred study methods and formats, supporting thoughtful, identity-aware research practices.
In parallel, we explored how social identity shapes the lived experiences of women in computing. This work surfaces the unseen labor and barriers they navigate daily—offering a deeper understanding of inclusion beyond representation.
Effect of Music on Pair Programming

Can background music boost collaboration and focus in remote software teams? This research explores how music influences the emotional and cognitive experience of developers during pair programming.
We are conducting an ongoing study that examines how different types of music affect mood, mental effort, communication, and productivity in collaborative coding. Our goal is to understand whether—and how—music can be used to improve teamwork and performance in remote environments.
By combining real-time physiological data with self-reflections and task outcomes, this research aims to uncover patterns that could guide music-aware tools and team practices. The results will help inform inclusive, flexible work environments for software teams working across distances.
Assessment of Programmers' Socio-Technical Skills
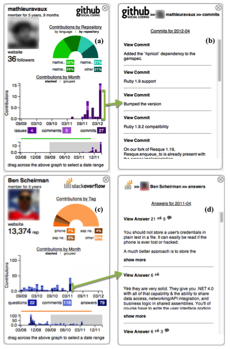
As hiring moves online, managers increasingly rely on public developer contributions to evaluate candidates. But in large, global communities like GitHub and Stack Overflow, surfacing relevant technical and social signals is a challenge.
To address this, we designed Visual Resume—a tool that aggregates developer activity across peer production platforms to create a more complete picture of programming expertise and collaboration style.
Visual Resume extracts and organizes key indicators such as commits, issues, and code diversity from GitHub, and combines them with Q&A, tags, and discussion behavior from Stack Overflow. This unified view highlights both technical skill and communication habits across platforms.
Our scenario-based study showed that participants valued the ability to view high-level summaries and also drill down into specific contributions to assess quality. This approach supports fairer, more informed evaluation of developers in hiring and recruitment.
Best Paper Award (ACM/IEEE ICGSE)
Understanding and Modeling Programmer's Explorations at File Level

Creative programming tasks—like writing, design, or prototyping—often involve exploring multiple versions of similar ideas. This kind of exploratory work can become cognitively demanding, especially for novice developers who need to compare, reuse, or refine variations of code.
To better understand how developers navigate variant-rich environments, we conducted a qualitative study focused on how programmers reuse similar code artifacts. Based on these insights, we developed PFIS-V, a predictive model of variation foraging that simulates how users move through spaces with many similar options.
PFIS-V improves prediction accuracy by up to 25% over prior models, helping us better model programmer navigation in complex information spaces. We later extended this work with PFIS-H, a computational model that accounts for the hierarchical structure of code and further improves navigation accuracy in file-level exploration.
These models offer a foundation for designing smarter developer tools that reduce cognitive load, especially in environments with high variation and exploratory tasks.
Best Paper Award (ACM CHI)
Mining Technical and Social Skills of Programmers
Programmers don't work in isolation—they learn, share, and collaborate through both technical contributions and social networks. This research uses social network analysis and deep learning techniques to understand how these two dimensions shape developer behavior.
We investigate how programmers learn from one another through their coding collaborations, and how they navigate across technical platforms like GitHub and social environments such as Stack Overflow. These insights reveal patterns of knowledge transfer and interaction across sites.
By mining these socio-technical signals, we aim to inform the design of intelligent tools that help developers discover trustworthy code and collaborators—based not just on code quality, but also on social connection and shared history.
Semantic Clone Detection using Source Code Comments

Code reuse boosts developer productivity—but it also leads to large fragments of duplicated or near-duplicated code scattered throughout the codebase. Detecting these "semantic clones" is essential for improving maintainability and reducing redundancy.
Traditional clone detection techniques rely on Program Dependency Graphs (PDGs), which, while effective, are computationally expensive and overlook one important source of meaning: source code comments. Despite their ambiguity, comments often contain rich domain knowledge that supports program comprehension.
This research explores lightweight alternatives by applying topic modeling (LDA) to source code comments, demonstrating that comments can be as effective as PDGs for identifying semantically related code. We propose combining comment-based file-level detection with targeted PDG analysis at the function level for more efficient and scalable semantic clone detection.
Supporting Problem Solving in End-User Programming

How do non-professional programmers learn to solve problems when they first encounter programming? Our research addresses this through the Idea Garden—a theory-driven approach based on Minimalist Theory that supports exploratory problem solving for end-user programmers (EUPs).
Idea Garden provides just-in-time scaffolding to help learners understand programming strategies, patterns, and concepts within the context of their own activities. By offering context-sensitive advice and mini-patterns, it helps EUPs move forward when they feel stuck.
We've developed a generalized architecture that allows Idea Garden to be embedded in a variety of learning environments. Our empirical evaluations—spanning think-aloud studies and summer camps with over 90 teen participants—demonstrated that learners needed significantly less in-person support while achieving the same learning outcomes. These results highlight the approach's flexibility and effectiveness across diverse learners, tasks, and platforms.
Supporting Exploratory Programming (Ph.D. Dissertation)
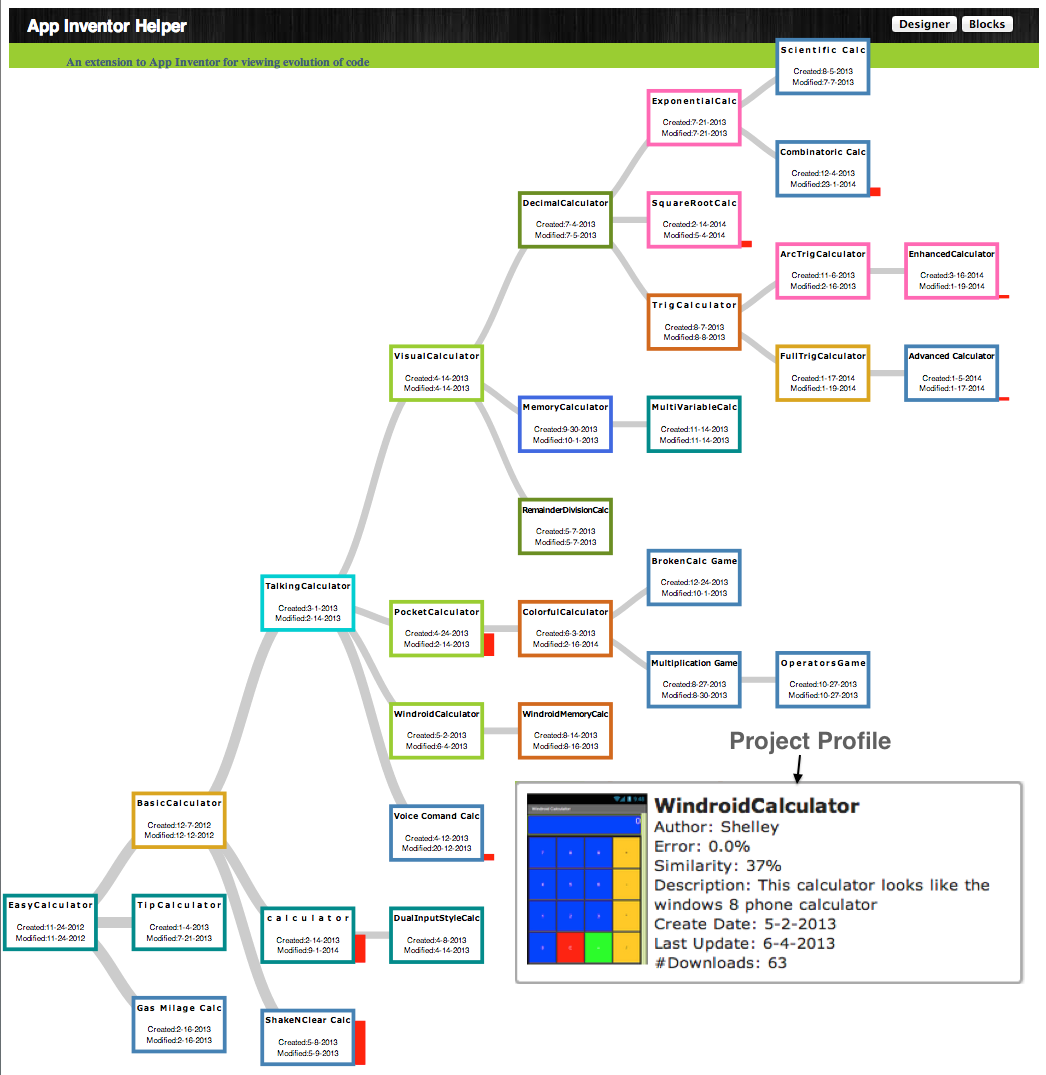
This research explores the foraging behavior of end-user programmers as they engage in exploratory programming tasks—such as program navigation, understanding, verification, and debugging—in environments rich with variations.
My work supports exploratory programming at three levels: workspace, file, and online repositories. As part of the multi-institutional Exploratory Programming project (with CMU, Oregon State, Nebraska, and UW), I developed tools such as AppInventorHelper for file-level support and Pipes Plumber for workspace-level debugging and navigation.
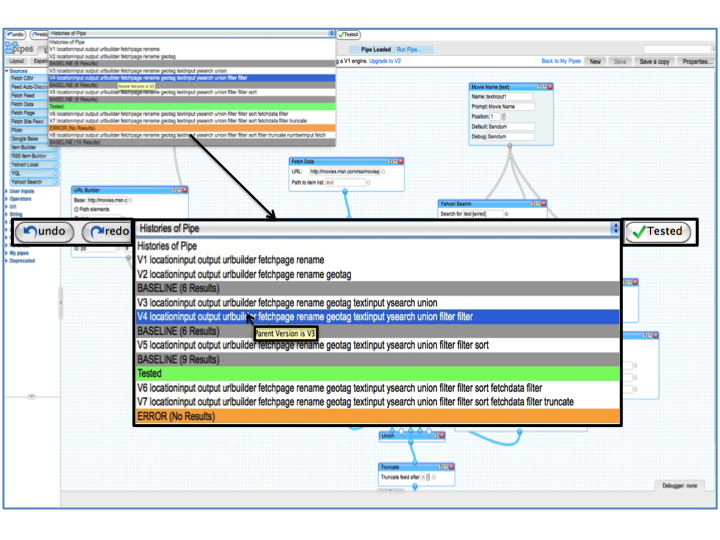
Supporting Debugging in Web-Based Distributed Programming Environments: The web presents a complex, content-rich space for developers building mashups with distributed APIs and dynamic content. My analysis of over 51,000 Yahoo! Pipes programs revealed that more than 64% contained bugs—mostly due to changes in source data. I introduced a classification scheme distinguishing intra-module and inter-module bugs, which informed the design of an anomaly detector for automatic bug detection.
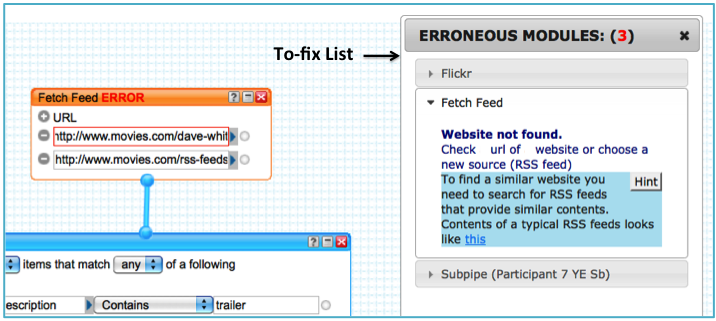
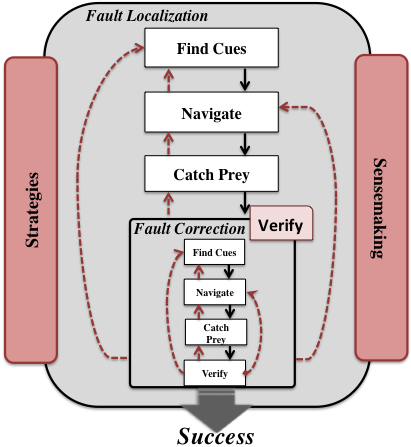
Using Information Foraging Theory (IFT): To understand how programmers debug mashups, I applied IFT—a theory that models information-seeking as foraging. In this context, programmers (predators) search for bugs (prey) using cues (e.g., labels, hyperlinks) in patches (e.g., web tools, IDEs). We extended the theory by modeling the distinct processes of fault localization and correction in web-based environments.
Click here to read more about my Ph.D. Dissertation.